

5 October 2022
by Michael Gronau, Lars Nock, Bratislav Milić
When launching a new major version of a product, it is common practice to prepare a set of new features. They are easy to present and provide something tangible to users and system administrators. While as important as new features, technical improvements such as code refactoring and architecture enhancements usually remain hidden or are at best seen as a sidenote in release notes.
In yuuvis® RAD version 7, however, we decided to focus on technical improvements that optimize parts of the server code and enhance the overall system architecture, making version 7 up to 5.8 times faster in certain metrics than version 6.16 LTS. This article quantifies the major refactoring that we performed on the workflow functionality in yuuvis® RAD and compares the two successive versions of our product to demonstrate the benefits of the new architecture.
In version 6 of yuuvis® RAD, the workflow logic was shared between two services: the core service was doing most of the work, implementing the logic of each step in the process execution (such as writing the history, handling the substitution rules, executing scripts, etc.). The bpm service controlled the activity processing within a process (moving a process from one state to another) and provided a REST interface for clients to list processes, see and manipulate their files, or to get the process history.
In our performance analysis of yuuvis® RAD 6, we observed that this setup was limiting to the level of asynchronicity that we were aiming for. Since the bpm service contained the logic that triggers the progress of a process to the next state, it had to make a blocking REST call that will just execute this transition in the core service. Since the REST call blocked the thread until it finishes (it was necessary to guarantee the correct ordering of execution of workflow steps), the bpm service was unable to fully utilize its threads and the overall workflow throughput was throttled down.
Starting with version 7, we decided to follow stricter rules of separation with regard to service responsibilities. The focus of the bpm service is now to provide clients with REST APIs to query processes, whereas the logic that controls the complete execution of processes is centralized in the core service. In consequence, inter-service communication, which occurred in yuuvis® RAD 6, can be completely avoided.
The main benefit of the new architectural solution brought by yuuvis® RAD 7 is that the delays introduced by the service-to-service communication over REST no longer exist. The state of a process is progressed with a simple call within the core service, and the threads are no longer blocked for longer time periods.
In addition to optimizations in architecture and code, the Java version in the yuuvis® RAD core service was updated from Java 8 in version 6 to Java 11 in version 7. Java 11 brings various new features, but for the purpose of this article the most important one is the improved garbage collector, which further increases the performance of the core service by several percent.
For benchmark execution, we used a workstation with an Intel Core i7-6700 CPU, 32 GB of RAM, and a Samsung PM871a 512 GB SSD. The core service executing the workflow functionality was limited through its configuration to only 2 GB of RAM. The database used by yuuvis® RAD for storage was MS SQL Server 2014 and was run on the same workstation.
For each of the tested scenarios, we start a batch of 1,000 processes and measure:
We then execute 50 of such batches and calculate the averages for the total batch time and for the single process execution.
These two metrics allow us to observe both changes in single-process performance and in overall server throughput when multiple processes are being executed in parallel.
This model contains no activities and its purpose is to measure the performance of process creation, finalization, and writing these events to the process history.

This benchmark clearly shows the improved utilization of the available threads in the corresponding services. While the execution time of a single process is comparable (which is to expect, since the executed steps are similar – initialize and finish a process and write history entries to database), we see a huge improvement in the overall execution time for a whole batch. Version 7 is capable of efficiently executing processes in parallel, thus reducing the execution time by a factor of 5. As explained before, version 6 was losing time on inter-service REST communication, which throttled down the overall throughput.
This model contains nine routes (in terms of process logic overhead, it is equivalent to an empty user work item in yuuvis® RAD, but easier to benchmark since no user action is required to move it to the next step). The purpose of this model is to measure and quantify the performance of forwarding of activities. It is representative of models that contain multiple user-related tasks, without intensive scripting being executed in work item events to implement complex business logic, where most of the system load is incurred due to the process transition from one step to the next.



The results further confirm the results from the first benchmark: the activities are getting delayed in version 6 during bpm service to core service communication, while version 7 benefits from a higher level of parallel execution and faster triggering of process progression through its state machine. We can see that execution times of a single process in both versions are comparable to the total execution time of the whole batch. This indicates that most of the process instances exist and are processed simultaneously. However, version 7 again benefits from the reduced overhead of inter-service communication and manages to finish a batch considerably faster.
The Script model (Figure 6) contains just one step with a single activity and an associated script. We use the route for the same reason as in the “Sequential model” scenario: to automate the process step forwarding. The activity contains a simple BeforeStartActivity script that writes some entries to the server log and then sleeps for 500 ms (Figure 7).
var p = $.process;
// log some attributes of the 'process'...
$.log.info('processId: ' + p.id); // id of the process
$.log.info('creator: ' + p.creator.id); // id of the user who started the process
$.log.info('creationTime: ' + p.creationTime); // time when the creator started the process
java.lang.Thread.sleep(500);
$.done();Figure 7: BeforeStartActivity script that emulates a typical script load on server
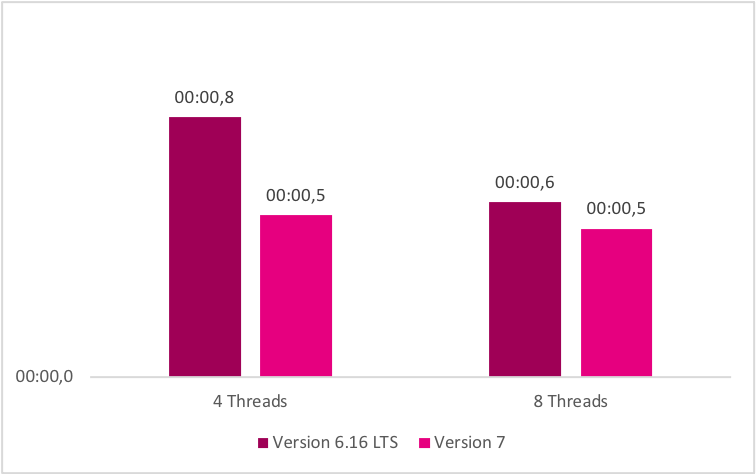
The purpose of this model is to measure the performance of script processing. Processing a script blocks the server thread during its execution, so we can both quantify the behavior of the server under heavy script load and how it utilizes its available threads. It is also a representative model for heavily scripted models that implement complex business logic. Also, as explained before, part of the processing logic was moved to the core service, which resulted in a much smaller communication overhead. This, however, increases the processing load on the core service in version 7, since it now also has to transition the states of the process state machine, a task that was executed by the bpm service in version 6. So, it was important to evaluate whether this slight increase in the processing load can affect the performance of computationally intensive processes, thus negating the positive effects that were observed in the previously analyzed scenarios.


The benchmark shows that there is no regression of version 7 in this scenario and that it retains advantages in comparison to version 6. Of particular interest is the measurement showing that the total execution time of a batch in a system with 4 processing threads in version 7 is only 27% slower than the execution time of a batch in a version 6 system with 8 threads.
This may be utilized by system operators either to improve workflow throughput in systems with version 7 (by keeping a high number of threads assigned to core service and workflow processing). The operator may also choose to remain at a comparable level of performance as in version 6. This can be achieved by reconfiguring the system in version 7 to run with only 4 threads and to assign the remaining four threads to other computationally intensive tasks in the yuuvis® system.
We optimized the architecture in version 7 and reduced the communication overhead between microservices to improve the overall performance of workflows.
The improvements made by version 7 are considerable and consistent in all analyzed scenarios. Improvements can be seen both on single-process performance (time needed to finish a single process in a batch) and on overall system throughput (time needed to finish a batch of processes).
For instance, in workflow models that generate a light processing load in their scripts, we observe the largest improvements – version 7 is up to 5.8 times faster than version 6.16 LTS. In processing-intensive workflows that contain complex business logic in their scripts, it is not possible to reduce the script run-time (the logic in scripts simply must be executed). However, even in this case, version 7 benefits from the optimizations performed and remains faster in every analyzed metric than the previous version of yuuvis® RAD.
OPTIMAL SYSTEMS is a
Group company of
Kyocera Document Solutions.
General Remarks
Software & Services
LOCATIONS
© Copyright OPTIMAL SYSTEMS 2024. | Legal & Data Privacy | Cookie-Settings